Data engineering is the backbone of modern data analytics. It ensures that data flows seamlessly from where it’s created to where it’s analyzed, empowering businesses to make data-driven decisions. But for beginners, the world of data engineering can feel like a maze of technical jargon. Don’t worry—this guide is here to clearly walk you through the essential data engineering terms, which is perfect for anyone new to the field.
What is a Data Pipeline?
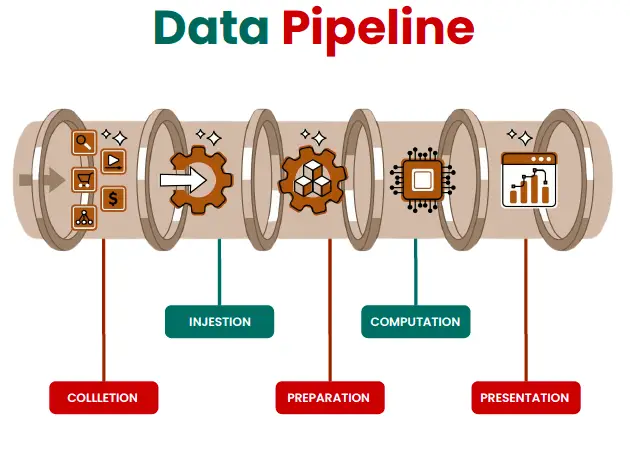
A data pipeline is the entire journey that data takes from being generated to being analyzed. Picture a water pipeline. Water is collected, transported, cleaned, and delivered to where it’s needed—data pipelines work similarly.
A typical data pipeline includes these stages:
- Collection: This is where the data originates. It could come from a variety of sources like websites, apps, IoT devices, or databases. Imagine you’re gathering rainwater from different streams—it all starts here.
- Ingestion: Once the data is collected, it’s brought into the system for further processing. Think of this as the water entering the main pipeline.
- Preparation: Now the data is “cleaned up” and organized. Any errors are corrected, duplicates are removed, and it’s structured in a way that makes sense for analysis.
- Computation: This is where the magic happens. You might perform calculations, apply algorithms, or transform the data into insights that can be used by business teams.
- Presentation: Finally, the processed data is delivered to its final destination—usually a dashboard or report where it can be analyzed and used for decision-making.
Data pipelines automate the entire flow, ensuring data is collected, processed, and made available in real-time or at scheduled intervals.
Database, Schema, and Table: What’s the Difference?
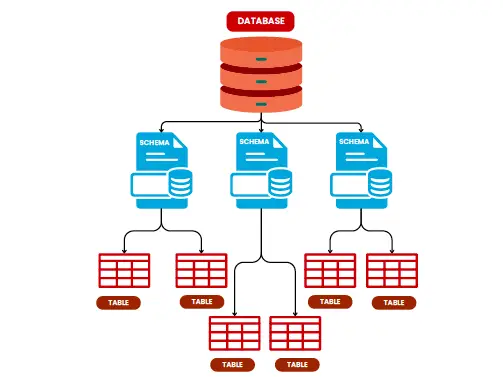
These terms come up a lot in data engineering, especially if you’re working with databases:
- Database: This is like a digital filing cabinet where all your data is stored. Think of it as a collection of organized data that can be easily retrieved, much like how you’d store and retrieve files from a physical cabinet.
- Schema: Inside a database, a schema is like a blueprint. It defines how your data is organized and structured. Imagine you’re building a house; the schema is the architectural plan that tells you where everything goes.
- Table: Within a schema, you have tables—this is where the actual data lives. A table looks like a spreadsheet, with rows and columns holding the individual pieces of data. If a database is a filing cabinet, a table is like a drawer where you keep documents in a specific order.
ETL vs. ELT: What’s the Difference?
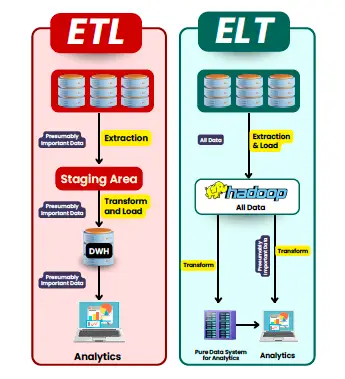
If you’re new to data engineering, you’ll often hear people talk about ETL and ELT. Both are processes for moving data from one place to another, but the order of operations is what sets them apart.
- ETL (Extract, Transform, Load): This is the traditional approach, where you first extract data from a source (like a database or an API), transform it into a suitable format, and then load it into a destination system (like a data warehouse). For example, you might extract sales data from an e-commerce platform, clean it up (transform), and load it into a database for analysis.
- ELT (Extract, Load, Transform): ELT flips the order. In this process, you extract the data and load it into the destination system first, and then you transform it there. This approach is increasingly popular with modern cloud data warehouses because they have the computing power to handle large amounts of raw data efficiently.
Which one should you use? It depends on your data infrastructure. ETL is great for smaller data sets or when you need clean data right from the start, while ELT is better suited for large, complex data environments.
Data Lake, Data Warehouse, and Data Mart: What’s the Difference?
These three terms describe different ways of storing data, each with its own purpose.
- Data Lake: Think of a data lake as a huge storage unit for all types of data—structured, semi-structured, and unstructured. It’s where you can dump raw data without worrying about organizing it right away. For instance, logs from web servers, social media posts, or sensor data could all be stored here. Data lakes are popular for advanced analytics, machine learning, and big data processing because they keep data in its original form until it’s needed.
- Data Warehouse: A data warehouse is a highly structured storage system optimized for fast querying and reporting. Data here is already cleaned, organized, and formatted for specific uses. It’s like a neatly arranged library with clearly labeled sections, making it easy to find exactly what you need. Data warehouses are great for business intelligence (BI) tools, which rely on structured data for generating reports.
- Data Mart: A data mart is a subset of a data warehouse, focused on a particular business function or department. For example, the marketing department might have its own data mart that contains only data relevant to customer interactions, ad campaigns, and website traffic. It’s more targeted and faster to query than the full data warehouse.
Batch Processing vs. Stream Processing: What’s the Best Way to Handle Data?
When dealing with large amounts of data, there are two primary ways to process it: batch processing and stream processing.
- Batch Processing: This is when you collect data over a period of time (say, an hour or a day) and then process it all at once. It’s ideal for tasks that don’t require real-time insights, such as analyzing historical trends or generating reports. For example, payroll systems often use batch processing to calculate employee wages at the end of each week.
- Stream Processing: Stream processing handles data in real-time, as it arrives. This is essential for situations where you need instant insights or actions, like monitoring fraud in banking transactions or tracking user behavior on a website. The key benefit is that stream processing delivers results in near real-time, giving businesses the ability to react immediately to critical events.
Understanding Data Quality
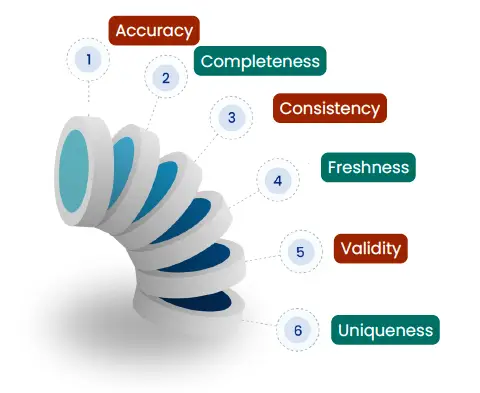
Data quality is all about ensuring your data is reliable, accurate, and useful. Poor quality data can lead to bad decisions, wasted resources, and missed opportunities. There are several key dimensions of data quality:
- Accuracy: The data must be correct and free of errors.
- Completeness: All necessary data should be present. Missing data can skew results.
- Consistency: Data should be consistent across different databases and systems. If you have different versions of the same data in different places, you have a consistency problem.
- Freshness: Data should be updated regularly to remain relevant. Outdated data might lead to wrong conclusions.
- Validity: Data should follow the correct format or rules. For example, if a field requires a date, the value should actually be a date.
- Uniqueness: Duplicate data can cause confusion and misreporting. Your data should be free of duplicates to ensure reliability.
What is Data Modeling?
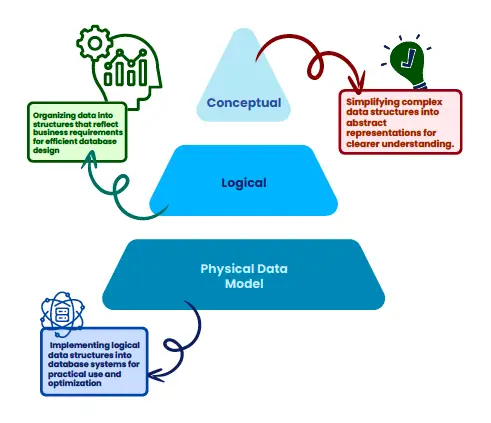
Data modeling is like creating a map of how your data is structured. It helps you design databases that efficiently store and organize data, making it easier to retrieve and analyze later. There are three main types of data models:
- Conceptual: This model is a high-level overview of what the data is and how it should be structured. It’s a simplified version used for planning.
- Logical: The logical model is more detailed, specifying exactly how the data will be organized in terms of tables, relationships, and rules.
- Physical: This is the implementation model—the actual database structure based on the logical model, including the tables, columns, and storage requirements.
Data Orchestration: How It Works
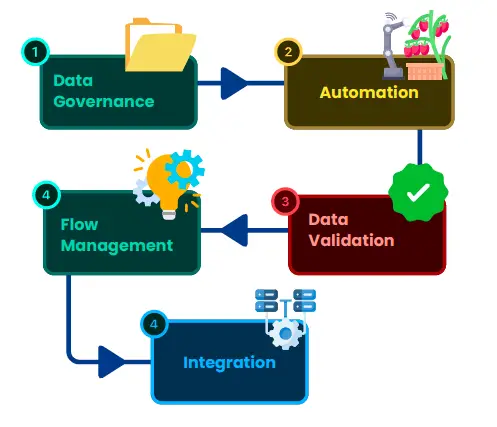
Data orchestration refers to the automation and coordination of data movement across different systems and environments. It’s what ensures that data flows smoothly from one place to another, whether you’re moving it between databases, applications, or cloud services. The goal of data orchestration is to make sure everything happens in the right order, at the right time, with minimal manual intervention.
Understanding Data Lineage
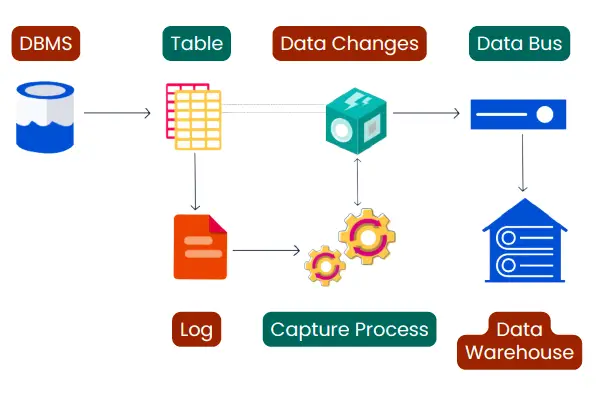
Data lineage provides a detailed view of the journey your data takes from its source to its final destination. It shows all the stops along the way, including any transformations or modifications. This is essential for ensuring data accuracy, maintaining compliance with regulations, and building trust in your data. Think of it as a GPS system for your data—it lets you see exactly where it came from and how it got to where it is.
Git: A Handy Tool for Data Engineers
Git is a version control system, most commonly used by software developers to track changes in code. However, it’s also incredibly useful for data engineers. Git allows you to keep track of changes in your data pipelines, scripts, and configurations, helping teams collaborate more effectively. By using Git, you can ensure that everyone on your team is working on the latest version of a project, and you can easily revert to previous versions if something goes wrong.
Final Thoughts
Getting familiar with these data engineering terms will give you a solid foundation for diving deeper into this exciting field. Whether you’re managing data pipelines, building data models, or ensuring data quality, understanding these concepts is essential. Bookmark this guide as your go-to reference for mastering data engineering!
Ready to learn more? Stay tuned for more deep dives into the world of data!
Feel free to share this guide with your friends or colleagues if you found it helpful. Happy learning!